Yes, you can sort in linear time, as long as you’re avoiding comparisons.
Radix sort and counting sort are two examples. They both avoid comparisons, and are possible because they sort based on grouping by a single element at a time, where that single element is a letter or digit (in mathematical terms, elements of a limited alphabet).
Comparison-based Bounds
Comparison based sorting will never be faster than O(n log n), because it’s bounded by the concept that comparison-based sorting as an element-by-element set of comparisons can be represented as a decision tree. For n sorted elements, at each node in the tree, we choose one of the n elements to be placed either before or after the other. This ends at the leaves, where there are n! possible leaves. Each leaf represents a permutation of an ordering of the elements.
A perfectly balanced binary tree with n! leaves has the height n log n.
Linear Sorting Given Special Restrictions
In my example of linear sorting, taken from Programming Pearls, by Jon Bentley, outlines a sorting problem, not limited by the runtime, but by space.
Task:
- Sort the numbers in a given file.
- Output the sorted numbers to another file.
Here are the conditions:
- There are at most 10,000,000 7-digit integers in the file, one on each line.
- There are no duplicates.
- You have only 1 MB of memory.
You can see some problems right away. If we have 10,000,000 integers, and each is a 32-bit integer, you’re dealing with 40 MB of data to sort. Just 1 MB? What is this? 1985? In this case, I think it was. The system’s overhead and other programs only allowed for 1 MB of space to sort the data. This was part of desktop software. Good luck.
The Solution
The solution is creative, and takes advantage of the fact there are no duplicates.
The solution the author comes up with is: store the integers in a bit vector. For each number in the file, turn on its corresponding bit in the bitmap. So if the number is 4762, flip the 4,762 + 1st bit (reserving 0 in case it shows up). Then once you’ve flipped all the bits on for each number in the file, iterate through the bitmap and output the corresponding bit index to a file.
This solution allows you to store 10,000,001 unique numbers (0 to 10,000,000) in only 10,000,001 / 32 bits = 312,501 bits.
Normally you wouldn’t think of this because of data loss. You’re turning a 32 bit integer into a single bit. But because integers are a built-in construct of programming languages and CPUs, we have a built-in way to reconstruct the data, and it costs no data space to do so.
Analysis
n: the number of items to sort
- Initializing a large bit vector to all zeroes: ~1.1*n operations (1 bit for each possible integer, even if that integer is not present in the input, here using 9,999,999 possible integers/9,000,000 unique numbers = 1.1)
- Reading the file: n operations
- Setting the bits: n operations
- Reading the bits from the bitmap: ~1.1*n operations (see above)
- Writing numbers to file: n operations
This gives us 5.2 * n operations, or O(n). Somewhere around 52 million operations.
Note, there are no comparisons involved in this algorithm.
If this were comparison-based, the most we’d hope for is O(n log n), where log210,000,000 = 23.25. n log n would make it approximately 232 million operations.
But operations aren’t really what we’re going for here. It’s limited space we’re worrying about.
Trying it out
A month after I read this solution, I went to implement it in Python. You’ll see a C implementation near the end of the post.
Generating millions of random numbers
I decided to try it with 9,000,000 unique numbers, from 0 to 9,999,999.
Here’s the code to generate the numbers into a file:
import random
def main():
numbers = random.sample(range(9999999), 9000000)
open("numbers.txt", "w")\
.write("\n".join(str(n) for n in numbers))
if __name__ == "__main__":
main()
This uses random.sample, which is perfect for generating unique numbers in a range.
This created a 71 MB file.
Implementation with list of integers
I created a Python class called Bitsort to implement the bitmap solution:
class Bitsort(object):
def __init__(self, max_number):
self._int_bits = 32
self._buckets = (max_number // self._int_bits) + 1
self._bit_array = [0] * self._buckets
def save_number(self, number):
bucket = number // self._int_bits
bit_number = number % self._int_bits
self._bit_array[bucket] |= 1 << bit_number
def get_sorted_numbers(self):
for index, bits in enumerate(self._bit_array):
base = index * self._int_bits
if not bits: # skips empty buckets
continue
for j in range(self._int_bits):
if bits & (1 << j):
yield base + j
def main():
bitsorter = Bitsort(9999999)
with open("numbers.txt", "r") as in_file:
for line in in_file:
bitsorter.save_number(int(line.rstrip()))
out_file = open("out.txt", "w", 4096)
for number in bitsorter.get_sorted_numbers():
out_file.write(str(number) + "\n")
if __name__ == "__main__":
main()
Python list storage analysis:
In Python, everything is an object, and uses memory multiples larger than the underlying primitive data types.
In order to make it easy to index into the right place to set/get bits, I used a Python list and indexed into a “bucket” where I could set the correct bit (from 0 to 31). The number of buckets: (max possible number // bits per integer) + 1.
That’s 312,500 buckets. I’m using a list to hold 312,500 integers.
Sizes:
- Empty Python list: 64 bytes
- Python list of 1 integer: 72 bytes (64 + 8)
- Python list of 2 integers: 80 bytes (64 + 8 * 2)
- Python list of 312,500 integers: 2,500,064 bytes (64 + 8 * 312,500)
So we’re already way over our memory allotment. There’s just too much object size overhead. However, it’s still much less than the 41 MB it would normally take if it was just a C-style memory slab. We’re using only 6% of the memory we’d normally use!
Profiling Memory
I used memory-profiler to see what kind of memory this sorting application was taking overall.
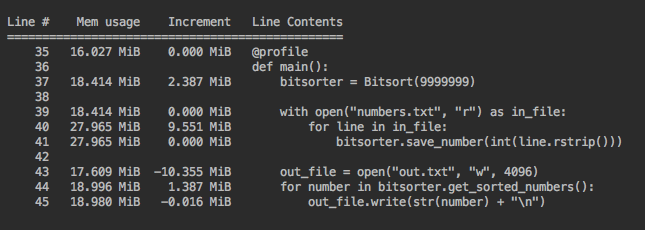
Memory usage peaks at 27 MiB, which is much higher than expected.
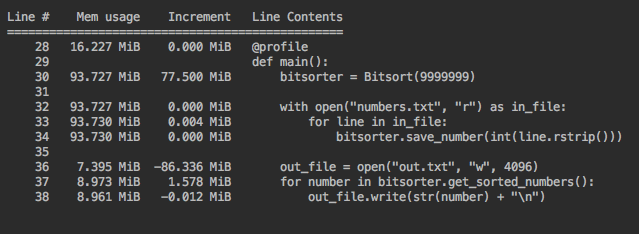
Implementation with bitarray
I then changed to use the bitarray module.
The class conversion to use it was pretty easy. Everything else stayed the same, due to good encapsulation.
import bitarray
class Bitsort(object):
def __init__(self, max_number):
self._int_bits = 32
self._bit_array = bitarray.bitarray([False] * (max_number + 1)) # 1 for 0
def save_number(self, number):
self._bit_array[number] = True
def get_sorted_numbers(self):
for index, bit in enumerate(self._bit_array):
if bit is True:
yield index
My expectation was that this would be more memory efficient. Not so much.
Trying it in C
So you want to use C and just get a slab of memory, eh pal? You know what you’re doing?
I took this code form the book, with minor modifications, running it as:
john$ clang -ggdb bitsort.c -std=c99 -Wall -Werror -o bitsort
john$ ./bitsort < numbers.txt > out.txt
#include <stdio.h>
#define BITSPERWORD 32
#define SHIFT 5
#define MASK 0x1F
#define N 10000000
int a[1 + N/BITSPERWORD];
void set(int i);
void clr(int i);
int test(int i);
int main(int argc, char *argv[]) {
int i;
for (i = 0; i < N; ++i) {
clr(i);
}
while (scanf("%d", &i) != EOF)
set(i);
for (i = 0; i < N; ++i) {
if (test(i)) {
printf("%d\n", i);
}
}
return 0;
}
void set(int i) {
a[i >> SHIFT] |= (1 << (i & MASK));
}
void clr(int i) {
a[i >> SHIFT] &= ~(1 << (i & MASK));
}
int test(int i) {
return a[i >> SHIFT] & (1 << (i & MASK));
}
I’ve used Valgrind for finding memory leaks for heap allocation/deallocation, but I wanted to find a tool for measuring total memory used.
I discovered Massif, and used it to output a memory graph. It’s normally used to do heap profiling, but the --stacks=yes flag can include stack usage.
On Ubuntu, I ran:
clang -ggdb bitsort.c -std=c99 -Wall -Werror -o bitsort && valgrind --tool=massif --stacks=yes ./bitsort < numbers.txt > out.txt
ms_print massif.out.8170
--------------------------------------------------------------------------------
Command: ./bitsort
Massif arguments: --stacks=yes
ms_print arguments: massif.out.8218
--------------------------------------------------------------------------------
KB
3.219^#
|#
|#
|#
|#
|#
|#
|#
|# :::::::::::::@: :: :@ ::::::@
|# :: :::::: :::@: :: :@ ::::::@
|# :: :::::: :::@: :: :@ ::::::@
|# :: :::: :::::@: : :::: ::: ::::@::: :: :::::: :::@: :: :@ ::::::@
|# :: : :: :::: @: : : :: : : :: :@::: :: :::::: :::@: :: :@ ::::::@
|# :::@: :: :::: @::: :: ::: : :@:: :@:::: :: :::::: :::@: :: :@ ::::::@
|# :::@: :: :::: @::: :: ::: : :@:: :@:::: :: :::::: :::@: :: :@ ::::::@
|# :::@: :: :::: @::: :: ::: : :@:: :@:::: :: :::::: :::@: :: :@ ::::::@
|# :::@: :: :::: @::: :: ::: : :@:: :@:::: :: :::::: :::@: :: :@ ::::::@
|# :::@: :: :::: @::: :: ::::: :@:: :@:::: :: :::::: :::@::::::@:::::::@
|# :::@: :: :::: @::: :: ::::: :@:: :@:::: :: :::::: :::@::::::@:::::::@
|#::::@: ::::::: @::::::: ::::: :@:: :@:::@@:: :::::: :::@::::::@:::::::@
0 +----------------------------------------------------------------------->Gi
0 13.37
It seems as though this is maxing out at 3.296 KB. I don’t know why. I may not be reading this right. There is probably some compiler super-optimization going on here. Not sure. Sorry for the inconclusiveness.
Call for Comment
Any thoughts or improvements? I like that I can wrangle an array in C with far fewer resources than in Python. I’d love to be able to have this kind of control in Python. Did I not use the bitarray module correctly?
Please comment below.
